Implementation and Analysis of Speech Recognition System Based on DSP
0 Preface
The purpose of speech recognition technology is to enable machines to understand human language and ultimately make human-computer communication a reality. In the past few decades, AutomaTIcSpeech RecogniTIon (ASR) technology has made significant progress.
ASR systems have been able to handle large vocabularies such as numbers from small vocabularies to broadcast news. However, for the recognition effect, the ASR system is relatively poor. Especially in conversational tasks, automatic speech recognition systems are far less than humans. Therefore, the application of speech recognition technology has become a highly competitive and challenging high-tech industry.
With the rapid development of DSP technology and continuous improvement of performance, the speech recognition algorithm based on DSP has been realized, and it has the advantages that PC does not have in terms of cost, power consumption, speed, accuracy and volume, and has broad application. prospect.
1 system parameter selection
In general, speech recognition systems have different classification methods according to different angles, different application ranges, and different performance requirements. There are isolated word recognition, connected word recognition, continuous speech recognition and understanding, and conversation speech recognition for different recognition objects. The vocabulary for the recognition system has small vocabulary speech recognition (1~20 vocabulary), medium vocabulary recognition (20~1 000 vocabulary) and large vocabulary (more than 1,000 vocabulary) speech recognition. According to the speaker range, it is divided into specific person speech recognition, non-specific person speech recognition, and adaptive speech recognition.
This paper mainly studies the non-specific small vocabulary continuous speech real-time recognition system.
1.1 Speech recognition system
Speech recognition is essentially a process of pattern recognition, that is, the mode of unknown speech is compared with the reference mode of known speech one by one, and the best matching reference mode is used as the recognition result. Speech recognition systems generally include front-end processing, feature parameter extraction, model training, and recognition. Figure 1 shows a block diagram of a speech recognition system based on the principle of pattern matching.
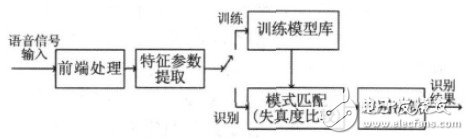
Figure 1 Basic block diagram of the speech recognition system
1.2 Characteristic parameters
The speech signal contains a very rich amount of information, including important information that affects speech recognition, as well as redundant information that is irrelevant to speech recognition and even reduces the recognition rate. Feature extraction can remove redundant information, extract acoustic parameters that accurately characterize speech signal features for model building and matching at the back end, greatly reducing storage space, training and testing time. For a specific person's speech recognition, it is hoped that the extracted feature parameters reflect the semantic information as little as possible, reflecting the speaker's personal information as much as possible, while for non-specific person speech recognition, the opposite is true.
The more commonly used characteristic parameters are linear prediction parameters (LPCC), line spectrum pair (LSP) parameters, Mel frequency cepstral parameters (MFCC), perceptually weighted linear prediction (PLP) parameters, dynamic difference parameters, and high-order signal spectrum classes. Features, etc., especially the LPCC and MFCC parameters are most commonly used. This paper chooses MFCC as the characteristic parameter.
1.3 Model training and pattern recognition
At the back end of the recognition system, a model parameter is formed from the known mode to represent the essential features of the pattern, and the pattern library is formed, and then the input speech is extracted from the feature vector parameter and compared with the established acoustic model, and according to the similarity, Certain expert knowledge (such as word formation rules, grammar rules, etc.) and discriminant rules determine the final recognition result.
At present, the model matching techniques applied in speech recognition mainly include dynamic time warping (DTW), hidden Markov model (HMM), artificial neural network (ANN) and support vector machine (SVM). DTW is a basic measure of speech similarity or dissimilarity and is only suitable for isolated speech recognition systems. It is dwarfed by the HMM algorithm when solving non-specific people, large vocabulary, and continuous speech recognition problems. The HMM model is a mathematical model of stochastic processes. It uses statistical methods to establish dynamic models of speech signals, and integrates acoustic models and language models into speech recognition search algorithms. It is considered to be the most effective model in speech recognition.
However, the SVM proposed by Vapnik and co-workers is based on structural risk minimization criteria and nonlinearities and functions, with better generalization ability and classification accuracy. Currently, SVM has been successfully applied to speech recognition and speaker recognition.
In addition, Ganapathiraju et al. have successfully applied support vector machines to complex large-word vocabulary non-specific continuous speech recognition. Therefore, this paper chooses SVM combined with VQ to complete speech pattern recognition.
2 system construction and implementation
In order to better reflect the real-time nature of the DSP, it is important to choose the appropriate parameters. Taking into account the storage capacity and real-time requirements of the DSP, this paper first selects the Matlab platform to simulate the system to compare and select the appropriate parameters.
2.1 Simulation Implementation on Matlab Platform
2.1.1 Establishment of experimental data
Based on the Matlab platform, the experimental speech signal in this paper is recorded by a normal microphone through the Windows audio device and Cool editing software in a quiet laboratory environment. The speech rate is moderate, the volume is moderate, and the file storage format is wav file. The voice sampling frequency is 8 kHz, and the sampling quantization precision is 16 bits, two channels.
Since there are 412 unvoiced syllables and 1 282 syllables. If SVM is used to classify all syllables, the amount of data is very large. Therefore, this paper selects 10 people to pronounce 6 unfixed consecutive Chinese numerals. 15 times, 900 samples after syllable segmentation, 600 samples were used as training sample sets, and the remaining 300 samples were used for identification of specific people. In addition, 5 people were selected to pronounce Chinese numbers 0-9, and each person pronounced 3 times. A total of 150 test samples were identified as non-specific people. In addition, the training or test samples selected above take into account the uniform distribution of 10 numbers from 0 to 9, and the sample types are manually calibrated.
2.1.2 Simulation and performance analysis of speech recognition system based on Matlab
Firstly, the speech signal is pre-processed and analyzed in time domain: pre-emphasis processing is performed using H(Z)=1-0.9375z-1; while considering the short-term stability of the speech signal, frame-by-frame windowing is adopted---Hamming window is selected The frame length is 32ms and the frame shift is 10ms. The system designed in this paper is a continuous vocabulary with small vocabulary. Considering the workload and the amount of calculation during training, the syllable is selected as the basic recognition unit. The speech feature parameter vector is composed of 12-dimensional MFCC, 12-dimensional first-order MFCC, and short-term normalized energy per frame.
This paper constructs a continuous speech recognition system based on SVM. The front end of the system adopts MFCC characteristic parameters, and uses genetic algorithm (GA) and vector quantization (VQ) hybrid algorithm to cluster the optimized codebook, and then the obtained codebook is used as the input of SVM mode training and recognition algorithm, according to the corresponding criteria. The result of the identification is finally obtained. The flow chart of the speech recognition system is shown in Figure 2.
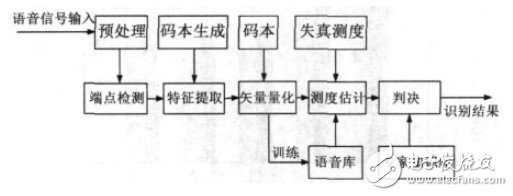
Figure 2 Speech recognition system flow chart
Firstly, the performance of speech recognition systems with different initial populations is analyzed. Table 1 shows the performance of the identification system under different initial populations. It can be concluded from the table that when the number of iterations is 100 and the initial population is 100, the final average fitness and positive rate of the population are the highest, followed by the initial population. Continue to increase, the average fitness and positive awareness rate are decreasing. Considering the time required for iteration and the positive recognition rate, this paper uses the initial population number of 80 to simulate and implement the system.
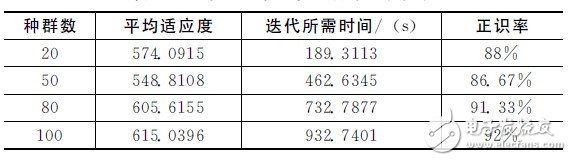
Table 1 Identification system performance under different initial populations
The number of population average fitness iterations required time / (s) The positive susceptibility rate system design takes into account the large amount of MFCC parameter data, which has a great influence on the time of model training and recognition. Therefore, vector quantization is selected to classify the data. The key problem of vector quantization is how to obtain the VQ codebook and the length of the codebook. The simulation is compared.
Table 2 gives a comparison of the effects of different VQ algorithms on the positive rate. From the table, the population number is 80, the codebook length is 16, and the kernel function is RBF. When the improved genetic algorithm (GA) is selected, the system's positive recognition rate is significantly higher than that of LBG and traditional GA.LBG is easy to fall into local optimum. Traditional GA has global search capabilities but slow convergence. The experiment proves that the improved GA solves the problems of the two well, the convergence speed is faster, and the positive knowledge rate is also obviously improved.
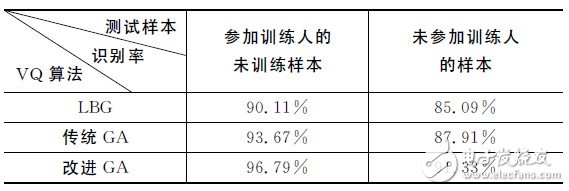
Table 2 Comparison of the influence of different VQ algorithms on the positive rate
On this basis, the effects of traditional GA and optimized GA on different codebook length distortion measures are compared, as shown in Figure 3. As can be seen from the figure, in the average distortion measurement of the codebook, the improved GA is significantly lower than the conventional GA, that is, the average fitness of the population is higher. It can also be seen from Fig. 3 that the distortion measure reaches the minimum when the codebook length is 32, but the value is reduced less when the codebook length is 16. Considering the iteration time problem, the codebook length used in this paper is 16.
Different SVM kernel functions also have an impact on the performance of the speech recognition system. The purpose of the SVM classifier is to design a class of hyperplanes with good performance to meet the multi-class data samples that can be distinguished by this class of hyperplanes in high-dimensional feature spaces.
It has been proved in the literature that the one-to-one classifier is more accurate than the one-to-many classifier in the boundary distance. Therefore, the one-to-one method is used to train and identify multiple types of data samples.
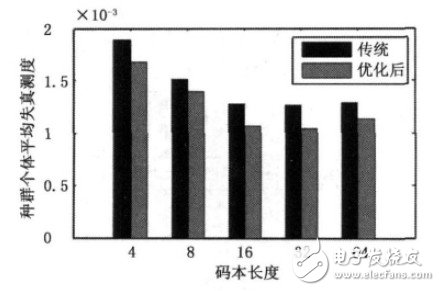
Figure 3 Comparison of distortion measurements of codebook length
Table 3 shows the identification system performance for different SVM kernel functions for non-specific people. The table shows that in the case of taking C = 3, γ = 125 (where 25 is the characteristic parameter dimension), although the number of support vectors required for the kernel function is RBF is slightly higher than the kernel function is Sigmoid, the system The correct recognition rate is significantly higher than that of other kernel functions, so RBF is chosen as the kernel function.
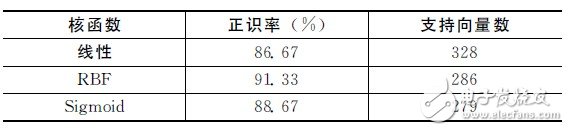
Table 3 Identification system performance of different SVM kernel functions
The effects of different vector quantization algorithms, SVM kernel functions and initial population numbers on the performance of speech recognition system are analyzed by Matlab simulation, which provides parameters and model selection for the realization of speech recognition system on DSP.
Diode TVS (Transient Voltage Suppressor), also known as Transient suppression diodes, is widely used a new type of high efficient circuit protection device, it has a fast response time (the nanosecond) and high surge absorbing ability.When it ends of stand moments of high energy shock, TVS can bring the two ends at high rate from high impedance to a low impedance between impedance values, to absorb a large current moment, put it at both ends of the voltage restraint on a predetermined value, thus protecting the back of the circuit components are not affected by the impact of the transient high pressure spikes.
Silicon TVS / TSS
Silicon TVS Transient Voltage Suppresso,Silicon TSS Transient Voltage Suppresso
YANGZHOU POSITIONING TECH CO., LTD. , https://www.yzpst.com